

文本自動校對是一項復雜的自然語言處理過程,包括拼寫檢查、真詞錯誤檢查、語法檢查、自動糾錯等內(nèi)容,是自然語言處理的基礎工作。從目前的研究現(xiàn)狀來看,藏文自動校對方法的研究文獻還不多,如多杰卓瑪[1]以線性化的藏文音節(jié)為研究對象,提出利用三元模型的藏文音節(jié)的校對方法,該模型丟失了藏文縱向拼寫的特征,也沒有校對效果進行實驗驗證。劉文香[2]提出藏文音節(jié)規(guī)則來校對藏文音節(jié)設想,但沒有具體的模型,也沒有相應的校對算法。才讓卓瑪?shù)萚3]利用藏文音節(jié)規(guī)則和分詞方法,提出音節(jié)和詞語校對的方案,區(qū)分音節(jié)、詞語和句子校對 3 種不同的類型。這些文獻對藏文文本的自動校對進行了初步討論,但沒有深入的研究藏文自動校對的特殊性,既沒有考慮錯誤的不同種類、藏文接續(xù)關系的特殊性,也沒有進行比較充分的實驗驗證。本文首先分析藏文文本中 5 種可能出現(xiàn)的錯誤:藏文音節(jié)拼寫錯誤、梵音轉寫藏文詞語錯誤詞語錯誤、接續(xù)關系錯誤和語法錯誤,在此基礎上,針對前 4 種錯誤類型,提出不同的錯誤識別方法,并通過實驗驗證方法的有效性,再進一步設計自動校對系統(tǒng)來驗證藏文自動校對框架的可行性。由于語法錯誤的復雜性,本文暫不進行探討。
1 藏文文本自動校對系統(tǒng)
藏文文本自動校對系統(tǒng)是一個復雜的系統(tǒng),包括藏文音節(jié)拼寫檢查、梵音轉寫藏文檢查、藏文接續(xù)關系檢查、詞語校對、語法語義檢查等內(nèi)容,貫穿自然語言處理領域的字處理、詞法分析、句法分析、語義分析的內(nèi)容。下面從藏文文本錯誤類型、校對系統(tǒng)框架設計和系統(tǒng)實現(xiàn)思路等方面進行描述。
1.1 藏文文本錯誤類型
英文文本校對中,常見的錯誤類型有非詞錯誤、真詞錯誤和句法語義錯誤。針對藏文的情況,本文定義了如下 5 種類型的錯誤。
定義 1 藏文音節(jié)拼寫錯誤是指不符合藏文字性組織規(guī)則的無效藏文音節(jié)。 例如“?????”寫成“????”,“?????”寫成“?????”等。這些錯誤可能是由于人為的輸入錯誤,或者正字法知識的缺陷,造成的拼寫錯誤。
定義 2 梵音轉寫藏文錯誤是指由音節(jié)點隔開的藏文字符串不符合梵音轉寫藏文文法規(guī)則的無效梵音轉寫藏文。例如“??????????????”寫成“???????????????”等。
定義 3 接續(xù)關系錯誤是指不符合藏文格助詞、不自由虛詞接續(xù)關系文法的連接錯誤。例如“????????????????”寫成“?????????????????”。
定義 4 詞語錯誤是指幾個正確的藏文音節(jié)搭配成詞語時, 該詞語不在藏文詞典集合中的無效藏文詞語。例如“?????????? ???????????????????”寫成“??????????? ?????????????????”等。一般出現(xiàn)在同音字代替正確字的場合,會導致意思的錯誤。
定義 5 語法語義錯誤是指不符合藏文語法結構規(guī)律或客觀事理的句子錯誤,包含語法錯誤和邏輯錯誤。例如“???????????”寫成“????????????”時態(tài)錯誤等。
根據(jù)上述的錯誤類型,本文從藏文音節(jié)拼寫檢查、梵音轉寫藏文錯誤檢查、接續(xù)關系檢查和藏文詞語錯誤檢查 4 部分進行探討,設計相應的藏文文本自動校對系統(tǒng)。
1.2 系統(tǒng)框架
藏文文本自動校對系統(tǒng)框架包含音節(jié)的拼寫檢查、梵音轉寫藏文檢查、接續(xù)關系檢查、藏文詞語校對、語法語義檢查等內(nèi)容。由于詞語的錯誤、梵音轉寫藏文的錯誤和接續(xù)關系的錯誤會導致語法語義錯誤,所以語法語義錯誤處于系統(tǒng)框架的底部,并與詞語錯誤、梵音轉寫藏文錯誤、接續(xù)關系錯誤進行關聯(lián)。藏文音節(jié)作為組成詞語單元,它的錯誤會導致詞語的錯誤, 因此音節(jié)拼寫錯誤放在詞語錯誤之上,表示音節(jié)錯誤與詞語錯誤的關聯(lián),具體系統(tǒng)框架如圖 1所示,其中虛線內(nèi)是本文討論的內(nèi)容。
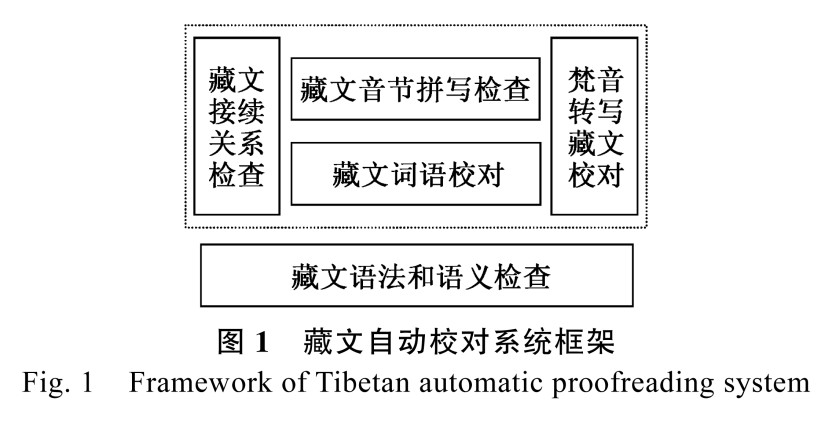
1.3 系統(tǒng)框架設計
在藏文文本校對系統(tǒng)設計過程中,每個模塊有明確的實現(xiàn)功能,但每個模塊之間也存在相互依存關系和執(zhí)行的前后順序問題。如何確定每個模塊之間的順序是系統(tǒng)設計的關鍵之一。
藏文文本中一般會出現(xiàn)傳統(tǒng)文法規(guī)則形成的藏文音節(jié)和梵音轉寫藏文。從表現(xiàn)形式上看,兩種字符串都是由音節(jié)點來隔開。在拼寫檢查時,不能用同一種規(guī)則方法來檢查拼寫的正確性。針對這個問題,首先需要明確藏文音節(jié)字符集合和梵音轉寫藏文字符集合的關系。由于傳統(tǒng)藏文文法和梵音轉寫藏文具有不同的文法體系,因此是兩個不同的字符組合關系。但畢竟這兩個集合是共同字符的兩種不同組合形式,所以兩個字符集合是一個大的集合中的不同子集,它們之間存在交集的部分,兩個集合關系如圖 2 所示,其中 A 是正確的藏文音節(jié)集合,B是正確的梵音轉寫藏文集合; A 和 B 的交集是共同擁有的正確的部分,圖中用交叉斜線部分表示;A∪B 的補集是藏文文本中字符組合錯誤的部分。
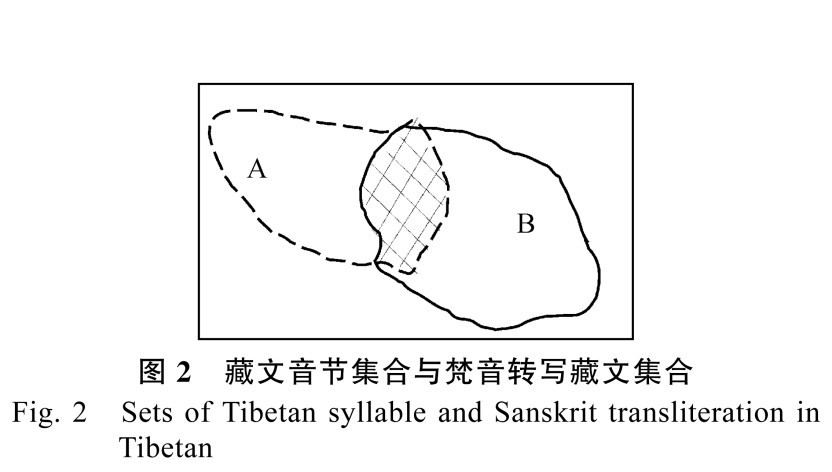
藏文音節(jié)拼寫檢查和梵音轉寫藏文錯誤檢查中,需要判斷音節(jié)點隔開的藏文字符串是否屬于 A或 B 集合。由于一般藏文文本中,藏文音節(jié)出現(xiàn)的頻率很高,而梵音轉寫藏文出現(xiàn)的頻率很低,如果先檢查梵音轉寫藏文,部分藏文音節(jié)作為梵音轉寫藏文而在接續(xù)關系檢查中無法檢查接續(xù)關系。因此,在檢查的順序上,本文認為先檢查藏文音節(jié),后檢查梵音轉寫藏文。
從總體框架上來,藏文文本校對系統(tǒng)通過采用模塊化的思想來逐一解決 4 種不同錯誤類型,具體實現(xiàn)算法如下,對應的藏文自動校對流程見圖 3。自動校對算法和流程圖表示每個模塊之間的先后順序和相互依存關系。
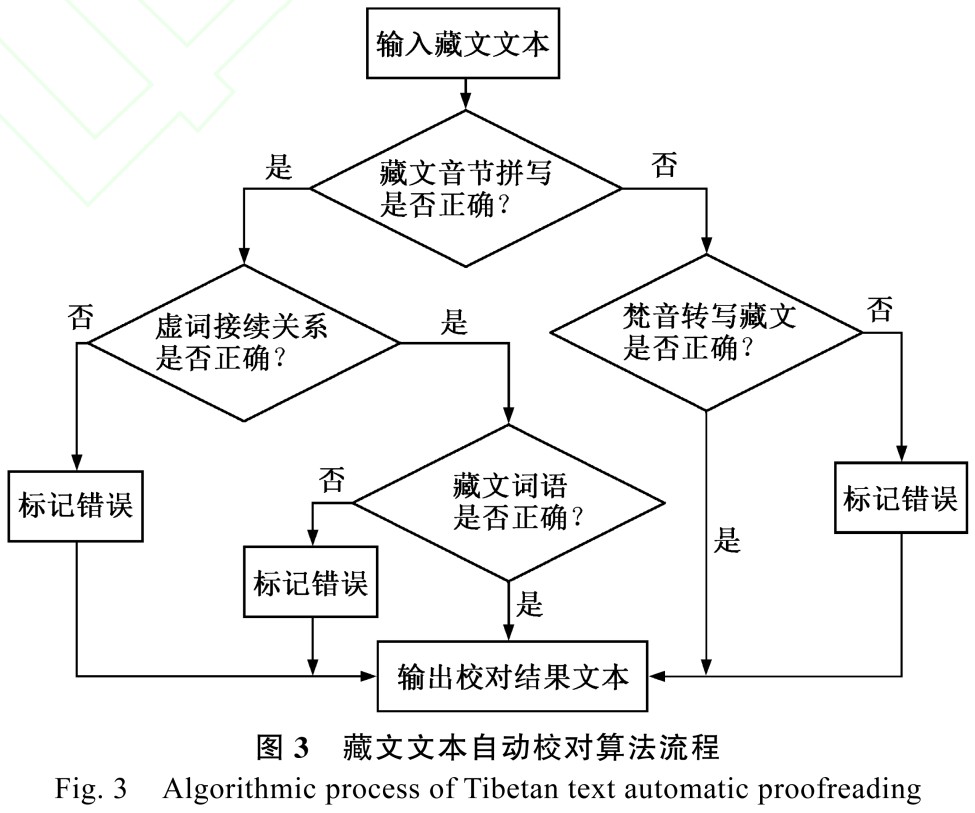
算法 1 藏文自動校對算法。
輸入: 藏文文本內(nèi)容;
輸出: 校對結果文本;
1 藏文音節(jié)拼寫檢查,若拼寫正確,轉到 3, 否則,轉到 2;
2 梵音轉寫藏文錯誤檢查,若正確,轉到 5,否則做標記錯誤,并轉到 5;
3 藏文的接續(xù)關系檢查,若接續(xù)關系正確轉到 4,否則做標記錯誤,并轉到 5;
4 藏文分詞,匹配詞典, 若匹配成功轉到 5,否則標記錯誤標記,并轉到 5;
5 輸出校對結果。
1.4 系統(tǒng)實現(xiàn)方式
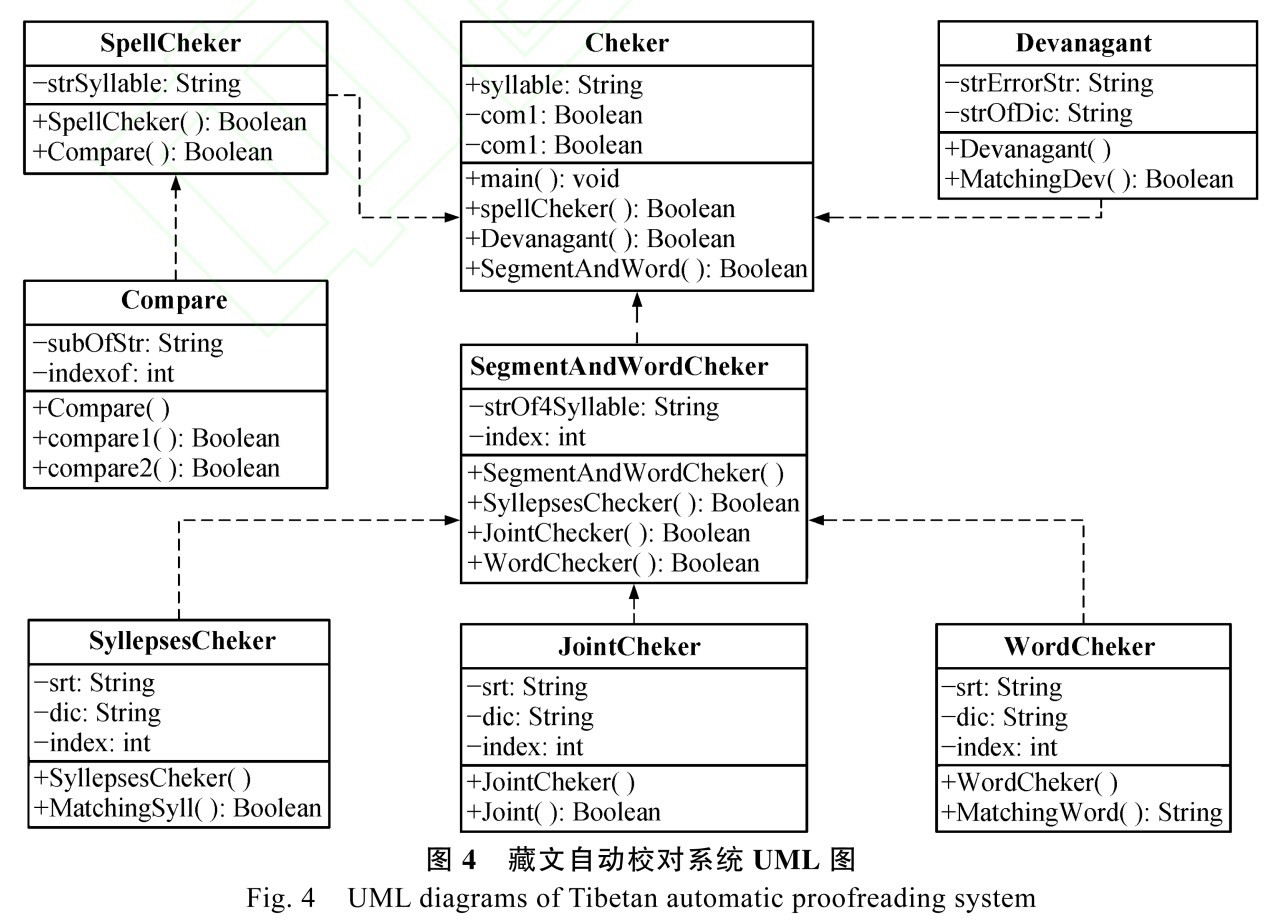
在系統(tǒng)的具體實現(xiàn)過程中,設計了 8 個類來實現(xiàn)不同的功能。Cheker 類為系統(tǒng)的主類,銜接藏文音節(jié)拼寫檢查、梵音轉寫藏文檢查、接續(xù)關系檢查和詞語檢查。主要功能由 3 個類來完成: SpellCheker類負責拼寫檢查, Devanagant 類負責梵音轉寫藏文檢查,SegmentAndWordCheker 類負責接續(xù)關系和詞語檢查。3 個類之間的關系為:首先,讀取一個藏文文本文件,并從該文件中按照順序獲取一個藏文音節(jié)。其次,一個藏文音節(jié)作為輸入條件,SpellCheker 類對該音節(jié)進行拼寫檢查,如果拼寫檢查錯誤,該音節(jié)交給 Devanagant 類來檢查梵音轉寫藏文的正確性;如果拼寫檢查正確,該音節(jié)交給 SegmentAndWordCheker 類。然后, Cheker 類中需要累積不低于 4 個的連續(xù)音節(jié), 這些音節(jié)作為 SegmentAndWordCheker 類處理的對象,檢查接續(xù)關系和詞語的正確性。在累積 4 個音節(jié)的過程中,出現(xiàn)拼寫錯誤或梵音轉寫藏文,處理的對象就按低于 4 個音節(jié)來處理。
在藏文音節(jié)拼寫檢查中,主要有 SpellCheker 類和 Compare 類來完成。SpellCheker 類完成拼寫檢查的內(nèi)容,Compare 類實現(xiàn)藏文音節(jié)規(guī)則模型算法的功能。Devanagant 類完成梵音轉寫藏文的詞典匹配功能,如果匹配成功,輸出梵音轉寫藏文,否則,輸出標記錯誤的藏文字符串。在接續(xù)關系檢查和詞語檢查中,藏文字符串和位置索引標記 index 作為輸入, SegmentAndWordCheker 類完成虛詞兼類過濾、匹配格助詞和不自由虛詞、匹配詞語的功能, 負責完成藏文接續(xù)關系和詞語正確性檢查。虛詞兼類由SyllepsesCheker 類來完成,排除存在歧義的可能性;接續(xù)關系的檢查由 JointCheker 類來完成,按照接續(xù)關系檢查算法,檢查格助詞和不自由虛詞接續(xù)關系的正確性;詞語檢查由 WordCheker 類來完成,采用
正向最大匹配分詞算法,檢查詞語的正確性,與分詞不同的是不再進行細切分,而且詞條的檢查只針對于雙音節(jié)以上的詞匯。系統(tǒng)實現(xiàn)過程的 UML 如圖 4 所示。
2 藏文文本校對方法
本節(jié)根據(jù)各個模塊自身的特性,具體探討每個細節(jié)過程,討論采用的具體方法,并著重討論接續(xù)關系的檢查算法。
2.1 藏文音節(jié)拼寫檢查算法
藏文音節(jié)拼寫檢查一般采取兩種方法: 第一種是收集所有可能的藏文音節(jié),然后采取字典匹配方式進行檢查;第二種是采用規(guī)則方法來進行拼寫檢查。本文利用藏文音節(jié)規(guī)則模型進行拼寫檢查[4]。
2.2 梵音轉寫藏文拼寫檢查方法
梵音轉寫藏文拼寫檢查方法中,根據(jù)專家整理的 13765 個梵音轉寫藏文字典為依據(jù),通過采用詞典匹配方法進行檢查。
2.3 藏文接續(xù)關系檢查算法
藏文具有豐富的格助詞和虛詞,其中虛詞又分自由虛詞和不自由虛詞。藏文接續(xù)關系中大部分格助詞和不自由虛詞具有嚴格的接續(xù)規(guī)則,不能隨意使用接續(xù)關系來進行詞與詞之間的連接。因此,接續(xù)關系檢查是藏文自動校對中是必不可少的環(huán)節(jié),也是與其他語種不同的特有現(xiàn)象。
傳統(tǒng)藏文文法中格助詞和不自由虛詞兩種接續(xù)關系,其中 5 個屬格助詞、5 個作格助詞、7 個位格助詞具有嚴格的接續(xù)關系;在不自由虛詞中 3 個飾集詞、3 個待述詞、11 個離合詞、11 個終結詞、“ ??? ”等 14 個虛詞、4 個時態(tài)助詞也具有嚴格的接續(xù)關系。接續(xù)關系的定義如下。
定義 6 后綴是指藏文音節(jié)的后加字、再后加字、無后加字 3 種類型的字符。
定義 7 接續(xù)關系是指針對藏文音節(jié)不同的后綴,格助詞和不自由虛詞嚴格遵守藏文后接添加規(guī)則,該規(guī)則稱為接續(xù)關系。
接續(xù)關系是傳統(tǒng)藏文文法的組成部分,也是1300 多年來一致沿用、藏文書寫必須遵守的規(guī)則。如果不按接續(xù)關系來書寫藏文,均視為接續(xù)錯誤。接續(xù)關系如表 1 所示, 該表是根據(jù)藏文文法收集和整理的藏文接續(xù)關系表。
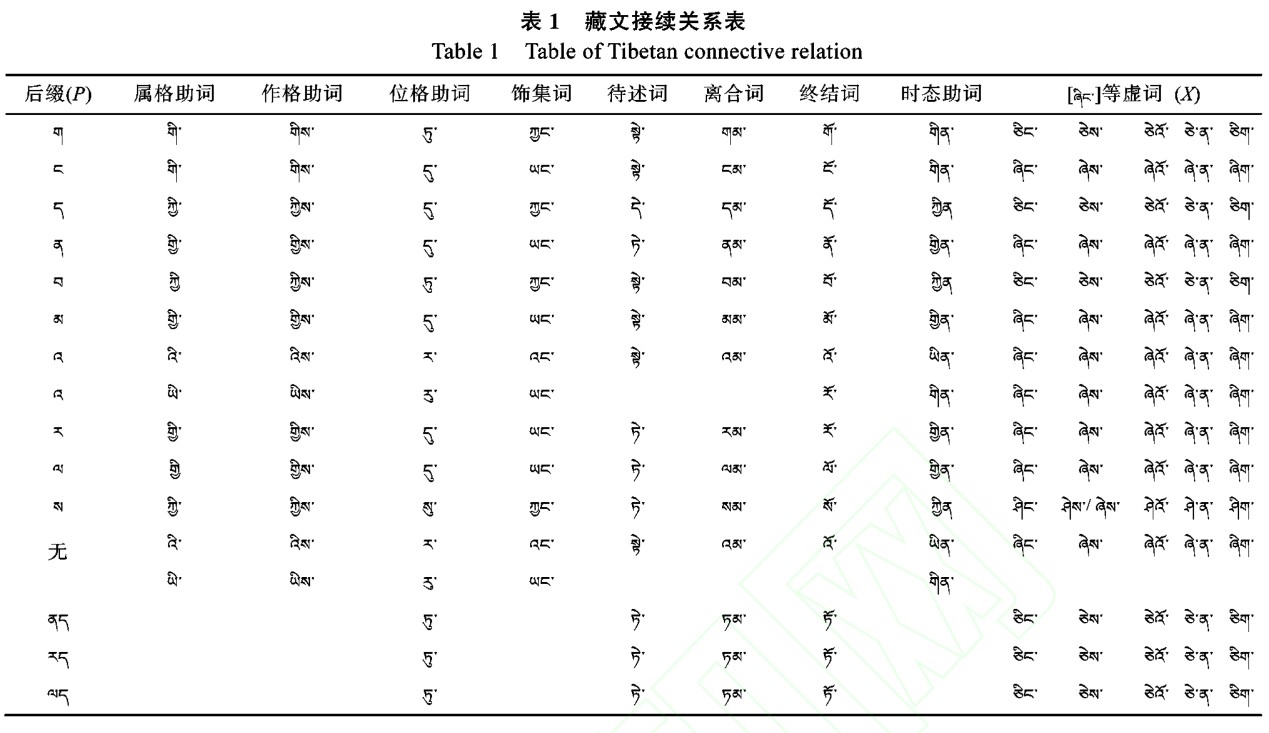
藏文接續(xù)關系用三元關系模型來進行形式化表示。P 為后綴集合, P={pi|pi∈{“?”, “?”, “?”,“?”, “?”, “?”, “?”, “?”, “?”, “?”, “Ф”, “ ??”, “??”,“??”}, i=1, …, n}; X 為包含格助詞和不自由虛詞的集合, X={xij|xij∈格助詞和不自由虛詞集合, i=1, …,n, j=1, …, m}。n 是后綴字符個數(shù), m 為格助詞和不自由虛詞個數(shù)。f 為接續(xù)關系函數(shù), xij=f(pi), 即某個pi
對應著多個可選的接續(xù)關系,只要滿足其中一個可選值,就是滿足藏文接續(xù)關系規(guī)則。
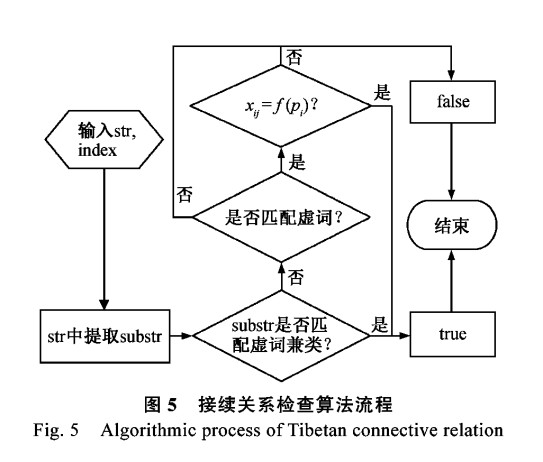
藏文音節(jié)拼寫檢查完成后,對正確的藏文音節(jié)檢查接續(xù)關系。從藏文音節(jié)結構分析,藏文音節(jié)的后綴存在3種不同的情況,即1個字符后綴、2個字符后綴和無字符后綴。因此,接續(xù)關系檢查中首先需要識別集合P中后綴的不同類型和具體后綴字符;其次需要識別集合X中格助詞和不自由虛詞;最后判斷是否滿足接續(xù)關系函數(shù)xij=f(pi)根據(jù)上面的考慮,藏文接續(xù)關系檢查算法如下。
算法2 藏文接續(xù)關系檢查算法。
輸入:輸入srt和index
輸出:True or False
創(chuàng)建字符串對象str //記錄讀取字符串,字符串的音節(jié)長度小于4
創(chuàng)建整數(shù)對象index //記錄文件讀取的索引位置
創(chuàng)建字符串對象substr //記錄str字符串的一個子串
創(chuàng)建字符串對象xij //存儲虛詞
創(chuàng)建字符串對象pi //存儲后綴字符
加載虛詞兼類詞典和接續(xù)關系表
if(substr是否為虛詞兼類) //過濾虛詞兼類情況,虛詞兼類匹配成功,返回true;否則,執(zhí)行下一步
{index←substr之后的索引位置
retun true
}
else if(substr是否屬于X) //是否與虛詞匹配,如果匹配成功,判斷接續(xù)關系;否則,執(zhí)行下一步
{pi←從srt中取出substr之前的最后第2個字符
xij←substr
swich(pi){ //匹配1個后綴字符的情況
case ?:{
if(xij==f(?)){return true;index←subsrt之后的索引位置}
else{return false;index←subsrt之后的索引位置}
}
…… //按照???????????????????逐一順序進行比對
case ?:{ //后綴字符為?
pi←從srt中取出substr之前的最后第3、2個字符
swich(pi){ //匹配2個后綴字符的情況
case ??:{
if(xij==f(??)){return true;index←subsrt之后的索引位置}
else{return false;index←subsrt之后的索引位置}
}
…
default
return falSe
}
}
default //無后綴字符的情況
{if(xij==f(pi)){return true;index←subsrt之后的索引位置}
else{returnfalse;index←subsrt之后的索引位置}
}
}
}
else
{return false;index←subsrt之后的索引位置}
藏文接續(xù)關系檢查算法中,為了算法描述的簡便,只檢查輸入一個字符串的情況,沒有加入循環(huán)嵌套的過程,但在實現(xiàn)算法時需要考慮循環(huán)過程。算法的流程如圖5所示。
2.4 藏文詞語錯誤檢查方法
藏文詞語正確性的檢查中,通過采用正向最大匹配算法進行詞典匹配,檢查雙音節(jié)以上詞語的正確性。與分詞不同,當詞典中的詞語不匹配時,不匹配的字符串項不再進行細分,只做錯誤標記。另外,在詞典內(nèi)容中去除單音節(jié),保留雙音節(jié)以上的詞條。采用197個虛詞詞典、2311個虛詞兼類詞典和 133227個藏文詞典。
2.5 測試
測試內(nèi)容包含接續(xù)關系檢查算法和系統(tǒng)部分的測試,主要檢查正確率、召回率和誤判率,并分析每個過程的測試結果。下面對幾個測試標準在文本中使用的方法做簡要介紹,然后分析實驗的測試結果。
2.5.1評測標準
在文本自動校對山,一般采用召回率、正確率和誤判率來評測文本校對算法的性能,具體公式[5]如下:
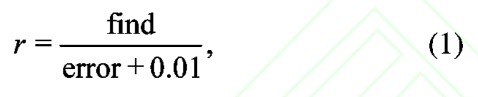
其中r為召回率;find為預校對文本中查出來的真正錯誤個數(shù),error為預校對文本中實際錯誤的個數(shù);0.01為平滑系數(shù)。

其中α為查準率;accurate為預校正文本中查出的正確詞判錯的個數(shù)。
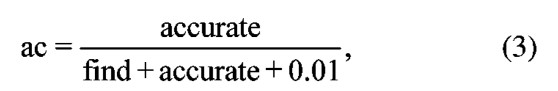
其中ac為誤判率。
2.5.2接續(xù)關系算法測試
為了測試接續(xù)關系算法,本文從“青海藏語廣播網(wǎng)”的留言板中收集語料,檢查接續(xù)關系算法的正確性、穩(wěn)定性和魯棒性。由于網(wǎng)上論壇、貼吧、博客等的內(nèi)容沒有經(jīng)過認真的審核和校對,撰寫人員的水平參差不齊,導致文本中經(jīng)常出現(xiàn)藏文音節(jié)拼寫錯誤、接續(xù)關系錯誤、詞語錯誤和語法錯誤,特別容易產(chǎn)生接續(xù)關系的錯誤。因此,這類語料的測試具有一定的代表性。語料按照不同留言數(shù)量,分為步長為10的6個文件,即第1個文件10個留言,第2個文件20個留言等。雖然采用步長10來平衡語料,但留言的內(nèi)容有多有少,很難得到均衡增長的目的。召回率、查準率和誤判率測試結果如表2和圖6所示。
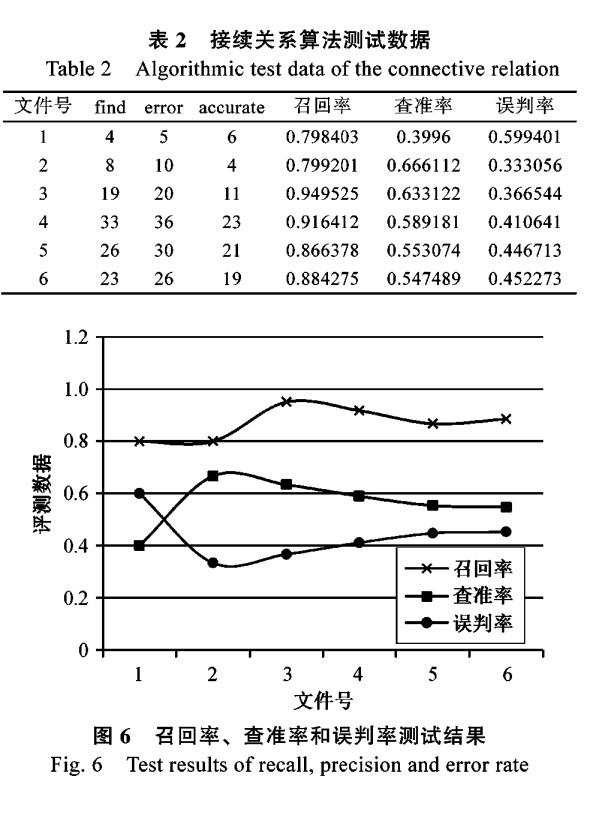
從實驗中可以發(fā)現(xiàn),接續(xù)關系算法的問題主要有以下幾種情形,下面通過具體的例子來進行說明。
例1 緊縮詞的識別問題。
格助詞和不自由虛詞中“???????????????”緊縮詞識別和還原,不僅存在識別的難度,還存在還原的難度,更存在接續(xù)關系判斷的難度,也是算法召回率和查準率降低的主要原因。例如 “ ???????????” 等。為了解決此問題,本文將緊縮詞的接續(xù)關系檢查納入到拼寫檢查模塊中, 然后進行接續(xù)關系檢查,但仍然存在“????” 的識別問題。表 3 的數(shù)據(jù)是改進后的測試結果。
例 2 無后加字的識別問題。
由于音節(jié)中沒有后加字而算法直接去尋找基字或元音, 如果音節(jié)中存在元音或者是縱向疊加情況,在后加字的判斷上就不會存在問題。如果既無元音, 又無疊加情況,基字又兼后加字時,算法會在無后加字的判斷上存在歧義。例如 “???????????????” 中 “??” 后加字還是基字會出現(xiàn)判斷失誤。
例 3 兩個后綴字符的識別問題。
在兩個后綴字符的識別上,例如 “??????????”、“???????”中,“???????”按兩個后綴字符來對待處理時,算法對此類語言現(xiàn)象的處理也是存在歧義的。
2.5.3 系統(tǒng)的性能測試
系統(tǒng)性能的測試中,涉及藏文音節(jié)拼寫檢查、梵音轉寫藏文校對、接續(xù)關系檢查、藏文分詞等多種校對技術, 每個模塊有自身的不足和缺陷,前面模塊的校對結果直接影響下一模塊的檢查結果, 因此系統(tǒng)的性能受各個模塊校對結果的影響,也受各個模塊之間相互關聯(lián)的影響。對 6 個文件召回率、查準率和誤判率語料測試結果如表 3 和圖 7 所示。
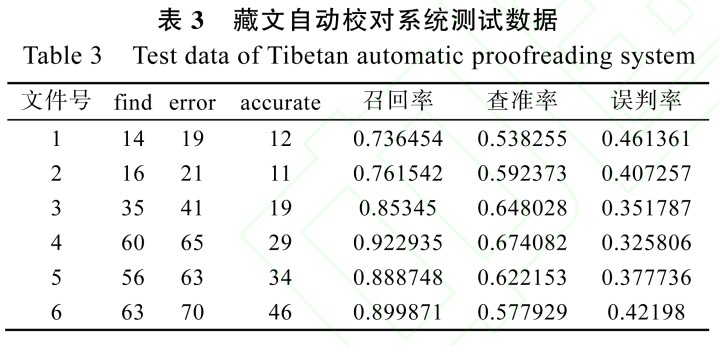
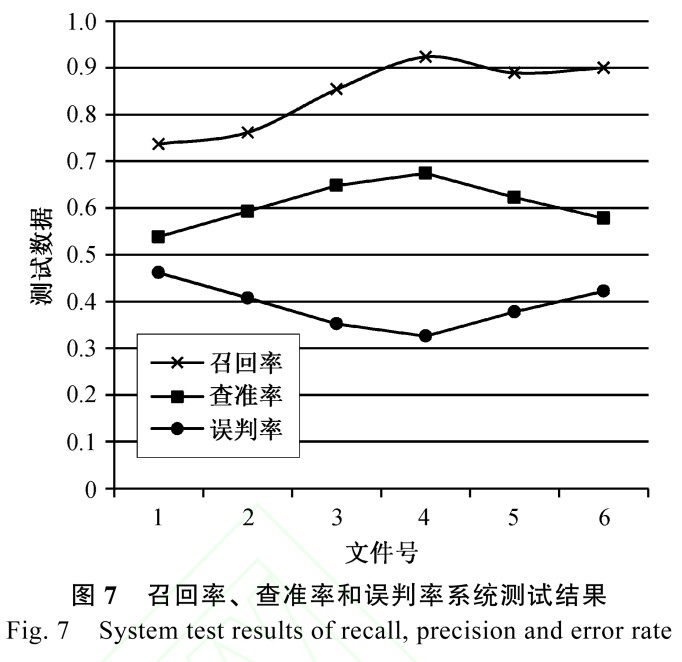
系統(tǒng)測試中存在各類錯誤, 包括分詞錯誤、接續(xù)關系中后綴字符識別錯誤, 拼寫檢查錯誤、各模塊交叉錯誤等。
3 結論與展望
藏文文本校對作為藏語自然語言處理的重要研究內(nèi)容, 涉及字組織法、詞法分析、句法分析等語言學中的主要理論, 不僅有助于藏文自然語言處理理論的提升, 而且在藏文文本檢查上有廣泛的應用領域。藏文音節(jié)拼寫檢查和梵音轉寫藏文主要應用藏文字性組織法理論; 藏文詞語檢查應用藏文詞法分析理論; 接續(xù)關系檢查和語法檢查應用句法分析理論和語義學的內(nèi)容。因此, 藏文文本校對技術的研究能夠比較完美地結合 3 個不同層面的理論。另外, 藏文自動校對可以應用在搜索引擎、文字處理、網(wǎng)上資源質量檢查等多種領域, 可以提高用戶的文字處理效率和文字質量, 提高網(wǎng)上資源的文本質量。因此, 本文以藏文音節(jié)拼寫檢查、梵音轉寫藏文檢查、藏文接續(xù)關系檢查、詞語正確性檢查為研究對象, 重點研究了藏文接續(xù)關系檢查算法、藏文文本自動校對的系統(tǒng)設計, 提出了接續(xù)關系檢查算法、自動校對的實現(xiàn)框架和算法, 通過實驗驗證了算法和實現(xiàn)框架的可行性和有效性。本文的研究,從不同的視角為藏文自動校對提供了實現(xiàn)方法, 從宏觀上來說還是屬于規(guī)則方法的文本校對方法。下一步的工作將繼續(xù)研究基于統(tǒng)計方法的藏文文本校對方法、基于規(guī)則和統(tǒng)計方法相結合的文本校對方法和藏文糾錯方法, 為藏文文本的查錯糾錯提供自動化的處理技術。
——————————————————————
參考文獻
[1] 多杰卓瑪. N 元模型在藏文文本局部查錯中的應用研究. 計算機工程與科學, 2009, 31(4): 117–119
[2] 劉文香. 藏文文本詞校對模型研究. 西藏大學學報:自然科學版, 2009, 24(2): 70–74
[3] 才讓卓瑪, 才智杰. 藏文文本自動校對系統(tǒng)開發(fā)研究. 西北民族大學學報: 自然科學版, 2009, 30(1):25–28
[4] 珠杰, 李天瑞, 劉勝久. TSRM的藏文拼寫檢查算法.中文信息學報, 已接受
[5] 張磊, 周明, 黃昌寧, 等. 中文文本自動校對. 語言文字應用, 2001, 1(2): 19–26
版權所有 中國藏學研究中心。 保留所有權利。 京ICP備06045333號-1
京公網(wǎng)安備 11010502035580號



